
药物研发的一个中心内容是药物分子与靶点蛋白之间的相互作用。寻找靶点对应的药物分子、评估药效、判断毒副作用……都是围绕着这对“主角”的相互作用展开的。2017年发表在Nature杂志的一篇报道称,有望成为药物的候选小分子的数量大约为1060个,是整个银河系原子数量总和(1054)的100万倍。
目前,研发一种新药从起步到上市大约需要14年的时间,平均成本是15亿美元。面对这浩渺无边的“银河系”寻药之旅,依托于生物实验的传统方法显然难以穷尽各种可能。
侯廷军教授是浙大药学院从事计算机辅助药物分子设计的专家,在过去的十几年中,他一直在探索把计算机技术用于药物研发。比如,根据已知靶点的信息对候选药物分子进行虚拟筛选,或者对成药性、毒副作用等进行预测。“但是,最大的挑战还是那些未知的靶点、未知的药物分子、未知的相互作用,我们应该怎么更高效地去发现呢?这需要方法上的新突破,这一步必须跨出去。”
方法上要升级,博士生一年级的叶青对此深有体会。“FDA目前批准的药物不足2000个,已经确证的药物靶点不足1000个。总体来说数量是很少,大部分的疾病还没有找到真正有效的药物。目前人们常用的办法主要是通过已知的药物分子去寻找药物靶标,或者通过已知的靶标蛋白的信息去寻找药物分子,但由于两者的数据集都非常稀疏,这些努力都被困在‘已知’里,发现新的药物-靶标相互作用的效率还没有达到预期,FDA每年获批的新药平均不会超过50个。”
图:药物靶标相互作用示意图
近年来,人工智能技术的发展让人们看到了新的可能。美国科学家埃里克·拓普(Eric Topol)在他的著作《深度医疗》中乐观地表示,成功识别并验证新型候选药物,是生物医学面临的最大挑战之一 ,而且它“具有人工智能的理想基质。”当前,许多科研机构、初创公司和制药企业开始利用人工智能的工具在药学版的“银河系”里大海捞针。
“借助人工智能,我们或许能到达药物研发更上游的环节。提升药物研发的效率和成功率。”侯廷军教授说。
除了人工智能,近年来基因组学、蛋白组学、药理学等生物信息技术也经历了快速发展。这些领域各自都积累了海量的生物医学信息。药物、蛋白质、疾病、副作用、生物过程、分子功能、细胞成分、生物酶、离子通道……所有这些信息都被存放在专业数据里,它们对于药物研发的价值仍然未知。
“直觉上说,大家都明白这些海量信息可能对药物研发的贡献,但关键是如何利用这些信息。”叶青本科学的是药学,从硕士研究生阶段开始,她就告别了瓶瓶罐罐的实验台,开始在计算机上推敲药物研发的方法;今年,她跨学科选择了博士生导师——控制学院的贺诗波教授课题组。
“这是一个特别适合交叉的领域。”贺诗波教授是长期从事大数据与网络科学研究的学者,在他眼中,这些海量的生物信息可以“抽象成一个多层的、异构的网络系统”,就像他同时在研究的电力系统、大脑神经网络一样,借助人工智能技术在这样的网络中进行知识挖掘和学习,并产生“新知”,意义重大。从去年开始,两位科学家开始了合作,尝试让人工智能去“消化”更多的生物信息,用于预测药物分子与靶标蛋白的相互作用。
“我们需要建立一个有效的网络模型,把这些异构的信息链接起来,其中各种生物信息是网络上的一个个节点,而数据之间的关系是网络上的一条条‘边’ 。”该项目合作者之一、控制学院陈积明教授说,生物信息领域的海量信息,有的可能是噪声的,有的可能是冗余的,希望设计这一系统能更好地将信息加以组织,从而把未知的线索挖掘出来。
这一预测系统名为“药靶图谱推荐系统”,它将知识图谱和推荐系统两种人工智技术相结合,“消化”能力更强了。这好比是警察抓小偷,过去的方法我们或许只能通过长相或者指纹来判断,而现代技术让我们记录到诸如通话记录、行动轨迹等周边信息,有效利用这些信息,在不知道小偷长相的情况下,也一样能锁定目标。
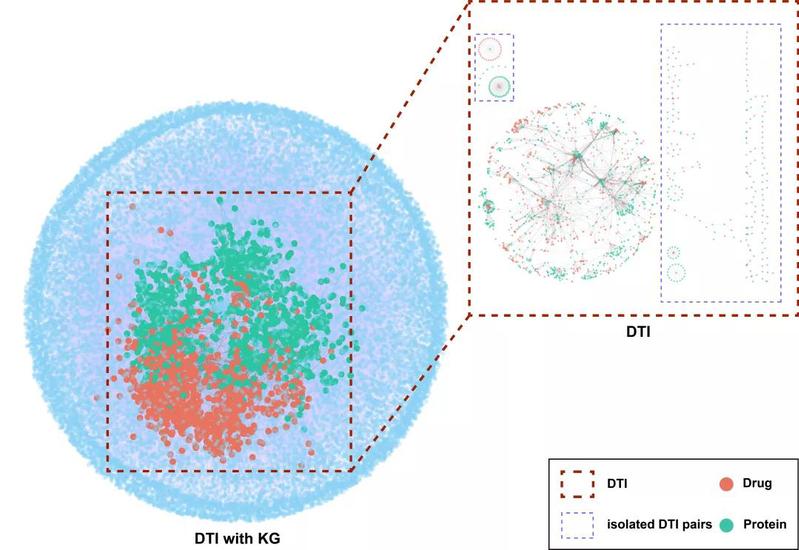
图:药物发现知识图谱(其中红色的点代表药物,绿色的点代表靶点,蓝色的点代表知识图谱中除去药物和靶点的实体,包括通路、基因注释等信息,灰色的线代表药物靶点相互作用,紫色的线代表知识图谱中除去物靶点相互作用的关系)
“药靶图谱推荐系统”首先通过知识图谱表征方法学习图谱中各种药物相关概念,然后通过神经因子分解机集成知识图谱中所学到的多组学信息和药物与蛋白的结构表征信息 ,最后输出它的预测结果——药物和靶点相互作用的概率排序。
恒温宽敞的房间,嗡嗡作响的服务器……药物、疾病、生命的相关数据库可能存放于世界任何角落。研究人员坐在计算机前就能远程访问它们,让自己训练的算法系统进行“学习”与“演练”。那么,“药靶图谱推荐系统”的表现如何呢?
四个公开的基准数据集成为“题库”与“赛场”,研究者将“药靶图谱推荐系统”与现有的三种预测模型以及传统的方法进行了一次全面的模拟竞赛。为了让比赛更贴近真实场景,研究将场景细分为三个场景:热启动(靶点和化合物信息都是已知的);对于药物的冷启动(根据已知的靶标蛋白信息寻找未知药物分子),对于蛋白的冷启动(未知靶标蛋白信息的情况下寻找药物分子)。
在前两项比赛中,人工智能算法与传统算法不相上下,甚至有时人工智能的算法略逊传统方法一些。而到了第三场景,“药靶图谱推荐系统”以领先30%的优势赢得了比赛。“这提示我们,恰恰是在从未知寻找未知,人类现有手段还有诸多束缚的领域,人工智能大有用武之地。”叶青说。
侯廷军教授认为,这关键的一局,体现了人工智能在面对未知领域的能力和优越性。从“未知”寻找“未知”,恰恰是未来人类药物研发中面临的主要场景。叶青认为,这得益于一个能“消化”海量生物信息的网络图谱。“当我们对未知靶点没有很多信息的时候,不知道它的结构如何,不知道它和什么药物分子能够结合,但它‘掌握’了更多组学方面的信息 ,这也许就是优势所在。”叶青说。
贺诗波说,采用人工智能进行复杂异构网络挖掘还有许多有趣的事可以做。比如,他们正在与腾讯实验室合作,致力于乙肝药物的虚拟筛选以及药物协同作用的研究。“知识图谱的运用,一方面是增加了信息的维度,另一方面可以增强算法系统的可解释性和可信度。”
论文信息
2021年11月,浙江大学药学院&智能创新药物研究院侯廷军团队、浙江大学控制学院贺诗波团队、中南大学曹东升团队和腾讯量子实验室联合在《自然·通讯》(Nature Communications)发表论文“A unified drug-target interaction prediction framework based on knowledge graph and recommendation system”,提出了一种基于知识图谱和推荐系统的药物靶标相互作用预测新方法。该方法高效地整合多组学的信息,为全新药物-靶标相互作用对的发现提供了功能强大的计算工具。浙江大学智能创新药物研究院和药学院为本论文的第一署名单位,控制学院博士生叶青和腾讯量子实验室谢昌谕博士为共同第一作者,浙江大学侯廷军教授、浙江大学贺诗波教授、中南大学曹东升教授为共同通讯作者。
原文链接:https://www.nature.com/articles/s41467-021-27137-3